인공 지능, 언어를 통해 인간의 편견까지 배우다
|

프린스턴 대학의 정보 기술 정책 센터 에일린 캘리스캔은 이렇게 말한다. “언어는 편견을 반영한다는 것이야말로 입증할 수 있는 주된 과학적 발견이다. 인공 지능이 인간 언어를 배우게 된다면 그 속에 숨어있는 편견도 반드시 배우게 된다. 언어는 세계의 문화적 사실과 통계를 반영하기 때문이다.”
캘리스캔, 그리고 공동저자 조안나 브라이슨, 아빈드 나라야난이 함께 한 연구는 지난 4월 ‘사이언스’ 지에 게재되었다. 이 연구에서 이들은 기계에 인간 언어를 가르칠 경우, 그 속의 편견도 함께 가르치게 된다는 것을 발견했다. 인간의 경우, 내재적 연관성 검사야말로 편견을 검사하는 가장 좋은 방법 중 하나다. 이 검사에서는 예를 들어 사람들에게 ‘곤충’이라는 단어를 제시하고, ‘불쾌하다’, 또는 ‘유쾌하다’ 중 하나와 연관 짓게 한다. 그리고 특정 단어가 다른 단어와 연관되는 속도를 살핀다. 사람들은 ‘곤충’을 ‘불쾌하다’와 연관 짓는 속도는 빠른 반면, ‘유쾌하다’와 연관 짓는 속도는 느렸다. 이는 내재적 연관성을 알아보는 좋은 척도다. 하지만 이렇게 망설임의 정도를 측정하는 것은 컴퓨터에게는 통하지 않는 수다. 때문에 연구자들은 특정 단어가 제시되었을 때 컴퓨터가 다른 단어와 연관 지으려는 경향을 얼마나 나타내는지 살폈다. 학생들은 뜻을 모르는 단어를 처음 봤을 때 그 단어와 함께 나오는 단어들의 뜻을 통해 그 뜻을 유추하려 한다. 연구자들은 그와 마찬가지로 인터넷에서 함께 사용되는 단어들끼리 연관 짓게 하고, 그렇지 않은 단어들끼리는 연관 짓지 않게끔 인공지능을 훈련시켰다.
각 단어를 3차원 공간 내 벡터라고 생각해보자. 같은 문장 내에서 흔히 쓰이는 단어는 가깝고, 별로 쓰이지 않는 단어는 멀다. 두 단어가 가까울수록, 기계가 연관 지을 확률이 크다. 예를 들어 사람들이 ‘프로그래머’를 ‘그’, ‘컴퓨터’와 함께 자주 말하고, ‘간호사’를 ‘그녀’, ‘의상’과 함께 자주 말한다면 이는 언어 속에 있는 내재적 편향을 나타내는 것이다.
|
|
이런 류의 언어 데이터를 컴퓨터에 입력해 컴퓨터를 학습시킨다는 개념은 새로운 것이 아니다. 스탠포드의 단어 표현 글로벌 벡터(Global Vectors for Word Representation, 이하 GloVe, 이 논문이 나오기 전부터 존재) 같은 도구들을 사용하면 관련 단어들의 사용방식에 근거해 벡터를 그린다. GloVe의 단어 집합에는 20억 개의 트윗에서 추출한 270억 단어, 2014년 위키피디아에서 추출한 60억 단어, 인터넷에서 무작위로 추출한 8400억 단어가 있다.
브라이슨은 말한다. “‘고양이라는 말 가까이에 끈이라는 말이 몇 번이나 나오는가?’ ‘개라는 말 가까이에 끈이라는 말이 몇 번이나 나오는가?’ ‘정의라는 말 가까이에 끈이라는 말이 몇 번이나 나오는가?’ 등을 알아볼 수 있다. 이는 단어 특성 부여의 일부다. 그리고 이러한 벡터들을 코사인과 비교해 볼 수 있다. 이로서 고양이와 개 사이의 거리, 고양이와 정의 사이의 거리를 알 수 있다.” 내재적 연관성 검사는 선악에 대한 무의식적인 생각을 개념화했을 뿐이다. 이와 마찬가지로 다양한 단어 묶음들 사이의 평균 거리 계산은 연구자들에게 컴퓨터가 언어를 배우면서 보이기 시작하는 편향성을 보여준다.
기계가 언어를 배우기 시작하면서 꽃(유쾌함)이나 곤충(불쾌함)에 대한 인간의 편견을 배우기 시작하는 것은 주목할만한 일이다. 브라이슨에 따르면 이 정도만 드러났어도 이미 중요한 연구라고 한다. 그러나 연구에서는 더욱 깊은 내용들이 드러났다.
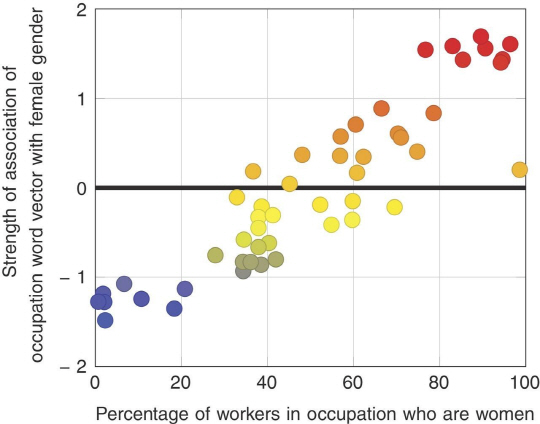
캘리스캔은 말한다. “그리고 두 번째 검사가 있다. 우리의 발견 내용과, 기존에 발표된 통계 사이의 양적 차이를 측정하는 것이다. 나는 2015년 노동청 통계를 찾았다. 이 통계를 보면 매년 직종별 여성 노동자의 비율은 물론 흑인 노동자의 비율도 나와 있다. 첫 번째 검사에서 나온 50개의 직업 이름과, 남성 또는 여성 간의 연관을 계산한 결과 노동청 데이터와 90%의 상관관계를 보였다. 매우 놀라운 일이었다. 이런 잡다한 데이터에서 이만한 상관관계를 보이리라고는 예상하지 못했다.”
그렇다면 컴퓨터도 직업 관련 단어를 특정 성별이나 인종 집단 관련 단어와 연관시키면서 인종주의와 성차별을 학습하고 있다는 얘기가 된다. 일례로 논문에서는 ‘프로그래머’의 사례를 들었다. 영어에서는 이 단어에 특별히 성별적인 의미가 부여되어 있지는 않으나, 남성적인 직업이라는 의미는 함축되어 있다.
브라이슨은 이렇게 말한다. “‘프로그래머’라는 말을 할 때 그 단어가 남성 혹은 여성을 뜻한다고는 생각지 않는다. 그러나 ‘프로그래머’라는 말이 일반적으로 쓰이는 맥락에서 그것이 어떤 성별을 자주 나타내는지가 드러났다.”
GloVe처럼 기존에 사용하던 언어 데이터 세트로 훈련을 받은 기계들은 이러한 연관성을 집어낸다. 그 속에는 이미 맥락이 존재하기 때문이다. 때문에 미래의 연구자들은 데이터 속에 인간적인 편견이 존재하는 점을 알고 그 사용에 주의를 기울여야 한다. 캘리스캔은 위키피디아에서 추출한 단어 집합을 사용하여 기계를 교육시킬 때, 중립적 언어 편집 규칙에 의해 편집된 위키피디아의 단어 집합 역시 인터넷에서 찾은 더 큰 단어 집합과 마찬가지의 편향성을 보여준다는 것을 알았다.
GloVe처럼 기존에 사용하던 언어 데이터 세트로 훈련을 받은 기계들은 이러한 연관성을 집어낸다. 그 속에는 이미 맥락이 존재하기 때문이다. 때문에 미래의 연구자들은 데이터 속에 인간적인 편견이 존재하는 점을 알고 그 사용에 주의를 기울여야 한다. 캘리스캔은 위키피디아에서 추출한 단어 집합을 사용하여 기계를 교육시킬 때, 중립적 언어 편집 규칙에 의해 편집된 위키피디아의 단어 집합 역시 인터넷에서 찾은 더 큰 단어 집합과 마찬가지의 편향성을 보여준다는 것을 알았다.
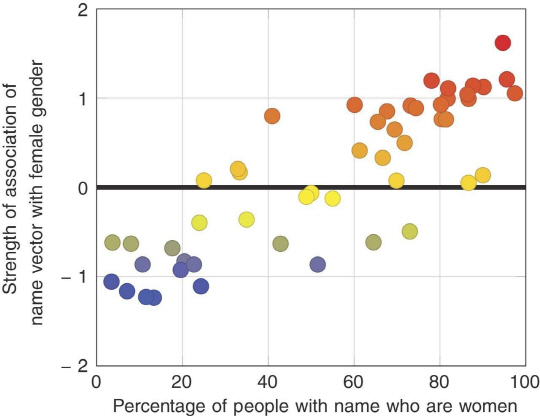
연구자들은 중성적 이름(알렉스나 테일러 등)을 찾다가, 인터넷에서 여성과 연관된 이름일수록, 그 이름이 여성에게 쓰이는 비율도 많다는 것을 알았다.
캘리스캔의 말이다. “편견의 존재를 인식하고 극복하기 위해서는 편견의 계량화가 필요하다. 언어 속에 편견이 어떻게 자리 잡는가? 과연 사람들은 언어에 노출되면서 편향된 연관짓기를 하게 되는가? 이러한 의문에 답을 해야 편견이 적은 미래로 나아갈 방법이 열릴 것이다.”
다른 언어를 살펴보는 것도 한 가지 방법이다. 이 연구는 인터넷상의 영어를 주로 관찰했으므로, 인터넷상의 영어 사용자들의 편견을 주로 발견했다고 볼 수 있다. 캘리스캔은 말한다. “우리는 여러 언어를 살피면서 그 언어들의 구문을 보고 그것들이 성적 고정관념이나 성차별에 영향을 미치는지를 알고자 한다. 어떤 것들은 중성적이지만 어떤 것은 성별의 차이가 있다. 영어의 대명사에는 성별의 차이가 있다. 독일어 같은 언어에는 명사에도 성별의 차이가 있다. 슬라브 계열 언어에는 형용사 및 동사에도 성별의 차이가 있다. 우리는 이러한 차이가 사회의 성적 편견에 영향을 미치는지를 알고자 한다.”
|

언어에는 변이성이 있다. 변이성이란 언어를 사용함에 따라 의미론적 맥락이 형성되는 방식이다. 때문에 인간이 세계를 이해하는 방식은 이것 말고도 또 있을 수 있다.
브라이슨의 말은 계속된다. “사람들은 새로운 현실을 만들고자 한다. 사람들은 이제까지 많은 것을 잘 모아 왔기에 여자들도 노동을 하고 경력을 쌓을 수 있는 세상이 되었다고 생각한다. 그것은 지극히 타당한 일이다. 그렇다면 이제는 새로운 합의를 이끌어 내야 한다. 예를 들어 한 사람의 프로그래머에 대해 말할 때도 ‘그(he)’가 아닌 ‘그들(They)’이라는 표현을 쓰는 것이다. 우리는 ‘어떤 사람들은 프로그래머가 될 수 없다.’는 느낌을 주고 싶지 않기 때문이다.” 그리고 사람들의 기존의 편견을 눈치 채지 못하고서 기계에 인간 언어를 프로그래밍 한다면, 편견 없는 기계를 만들 수 없다. 인간의 편견을 복제하는 기계를 만들 것이다.
캘리스캔의 말이다. “많은 사람들은 기계는 중립적이라고 생각하지만 그렇지 않다. 기계 학습처럼 연속해서 결정을 내리는 순차 알고리즘은 인간 데이터가 입력된 것이다. 따라서 그 데이터를 표시하고 반영할 수밖에 없다. 그리고 과거 데이터에는 편견이 개입되어 있기에, 우수하고 정확하며 모든 연관성을 파악할 수 있는 학습 알고리즘이라면 데이터 속의 편견이 나올 수밖에 없다. 기계 학습 시스템은 본대로 학습할 수밖에 없다.”
서울경제 파퓰러사이언스 편집부 / by Kelsey D. Atherton
Copyright © 서울경제. 무단전재 및 재배포 금지.
- 문재인 대통령, 4대강 사업 정책감사 지시..6월부터 보 상시 개방
- [전문]문재인 대통령, 노무현 전 대통령 추도식 인사말
- 김민희 홍상수 맞담배까지? 최여진 "내가 홍상수 아내면 김민희 죽여버렸을 것"
- '돌아온 최고 칼잡이' 윤석열, 첫 출근하자마자 곧바로
- "제 이상형" 윤석열 극찬 '전여옥' 감동한 결정적 이유
- 요즘 '벤츠·BMW' 타는 사람 참 많더니만 끝내 이렇게
- 울먹인 최순실 외면 '박 전 대통령' 막내린 '40년 우정'
- '고졸신화' 김동연 부총리 후보자 감정에 북받친 이유
- [단독] 가양동 옛 CJ부지 '제2 코엑스' 흔들
- 美 3월 PCE 전년比 2.7%↑…아직도 불안한 물가